The Google File System
Sanjay Ghemawat, Howard Gobioff, and Shun-Tak Leung (SOSP 2003)
Google needs a distributed file system that matches its applications needs. Solution: GFS.
GFS: Scalable distributed file system for large distributed data-intensive applications.
Why are we reading this paper?
- Distributed storage is a key abstraction
- Incorporates many of the recurring themes in Distributed Systems:
- parallel performance
- fault tolerance
- replication and
- consistency.
- Successful real-world design(Academics didn’t use single master). BigTable, MapReduce built on top of GFS.
- Well-written systems paper - details from the application to the network.
- Successfully applied the single master and weak consistency.
Why is distributed storage hard?
- high performance ⇒ shard data over many servers (To achieve high performance, a common strategy is to shard data over many servers)
- many servers ⇒ constant faults (Having many servers lead to constant faults)
- fault tolerance ⇒ replication (To implement fault tolerance, one strategy is to make use of replication)
- replication ⇒ potential inconsistencies (With different replica of the same data, however, potential inconsistencies between each replica will occur)
- better consistency ⇒ low performance
In GFS, we will see that consistency is traded off for simpler design, greater performance, and high availability.
What would we like for consistency?
- Ideal model: same behavior as a single server
- Ideal server executes client operations one at a time; even if multiple clients issued operations concurrently
- reads reflect previous writes even if server crashes and restarts all clients see the same data
- thus: suppose
C1andC2write concurrently, and after the writes have completed,C3andC4read. what can they see?C1:Wx(1)C2:Wx(2)C3:Rx?C4:Rx?
- answer: either
1or2, but both have to see the same value. - This is a “strong” consistency model.
Replication for fault-tolerance makes strong consistency tricky.
- a simple but broken replication scheme:
- two replica servers, S1 and S2
- clients send writes to both, in parallel
- clients send reads to either
- In our example, C1’s and C2’s write messages could arrive in
- different orders at the two replicas
- if C3 reads S1, it might see x=1
- if C4 reads S2, it might see x=2
- or what if S1 receives a write, but
- the client crashes before sending the write to S2?
- that’s not strong consistency!
- better consistency usually requires communication to
- ensure the replicas stay in sync – can be slow!
- lots of tradeoffs possible between performance and consistency
GFS Key Ideas
Motivating Example
- Crawl the whole web
- Store it all on “one big disk”
- Process users’ searches on “one big CPU”
- More storage, CPU required than one PC can offer
- Custom parallel supercomputer: expensive (so much so, not really available today)
Cluster of PCs as Supercomputer
- More than 15,000 commodity-class PC’s.
- Multiple clusters distributed worldwide.
- Thousands of queries served per second.
- One query reads 100’s of MB of data.
- One query consumes 10’s of billions of CPU cycles.
- Google stores dozens of copies of the entire Web!
Conclusion: Need large, distributed, highly fault-tolerant file system.
Serving a Google Search query
Steps in query answering:
- DNS picks out a cluster geographically close to user.
- A Google Web server machine (GWS) at the cluster is chosen based on load-balancing.
- Query is sent to index servers. Each index holds inverted index for a random subset of documents.
- Index server returns list of docid’s, with relevance scores, sorted in decreasing order.
- GWS merges lists, gets overall list sorted by query.
- Full text of actual documents are divided among file servers. GWS sends each file server the query plus the list of docid’s on that server.
- File server returns document summary for that query (excerpt containing query word with query words highlighted)
- GWS assembles summaries, advertisements from ad server, spelling correction suggestions, returns to user.
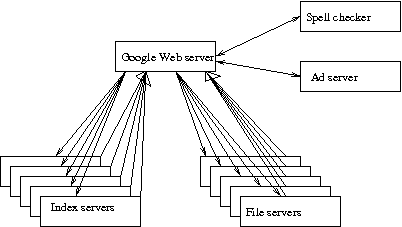
“On average, a single query in Google reads hundreds of megabytes of data and consumes tens of billions of CPU cycles. Supporting a peak request stream of thousands of queries per second requires an infrastructure comparable in size to that of the largest supercomputer installations. Combining more than 15,000 commodity-class PC’s with fault-tolerant software creates a solution that is more cost-effective than a comparable system build out of a smaller number of high-end servers.”
Google Platform Characteristics
- 100s to 1000s of PCs in cluster
- Cheap, commodity parts in PCs
- Many modes of failure for each PC:
- App bugs, OS bugs
- Human error
- Disk failure, memory failure, net failure, power supply failure
- Connector failure
- Monitoring, fault tolerance, auto-recovery essential
Design Motivations
- GFS runs on a large number of machines. Failures occur regularly, so fault-tolerance and auto-recovery need to be built in.
- File sizes are much larger. Standard I/O assumptions (e.g. block size) have to be reexamined.
- Record appends are the prevalent form of writing. Need good semantics for concurrent appends to the same file by multiple clients.
- Google applications and GFS are both designed in-house - so they can and should be co-designed.
Google File System: Design Criteria
- Detect, tolerate, recover from failures automatically
- Large files, >= 100 MB in size
- Large, streaming reads (>= 1 MB in size)
- Read once
- Large, sequential writes that append
- Write once
- Concurrent appends by multiple clients (e.g., producer-consumer queues)
- Want atomicity for appends without synchronization overhead among clients
What were the problems GFS was trying to solve?
Google needed a large-scale and high-performant unified storage system for many of its internal services such as MapReduce, web crawler services.
In particular, this storage system must:
- Be global. Any client can access (read/write) any file. This allows for sharing of data among different applications.
- Support automatic sharding of large files over multiple machines. This improves performance by allowing parallel processes on each file chunk and also deals with large files that cannot fit into a single disk.
- Support automatic recovery from failures.
- Be optimized for sequential access to huge files and for read and append operations which are the most common.
In particular, GFS is optimized for high sustained bandwidth (target applications place a premium on processing data in bulk at a high rate), but not necessarily for low latency (GFS is typically used for internal services and is not client-facing).
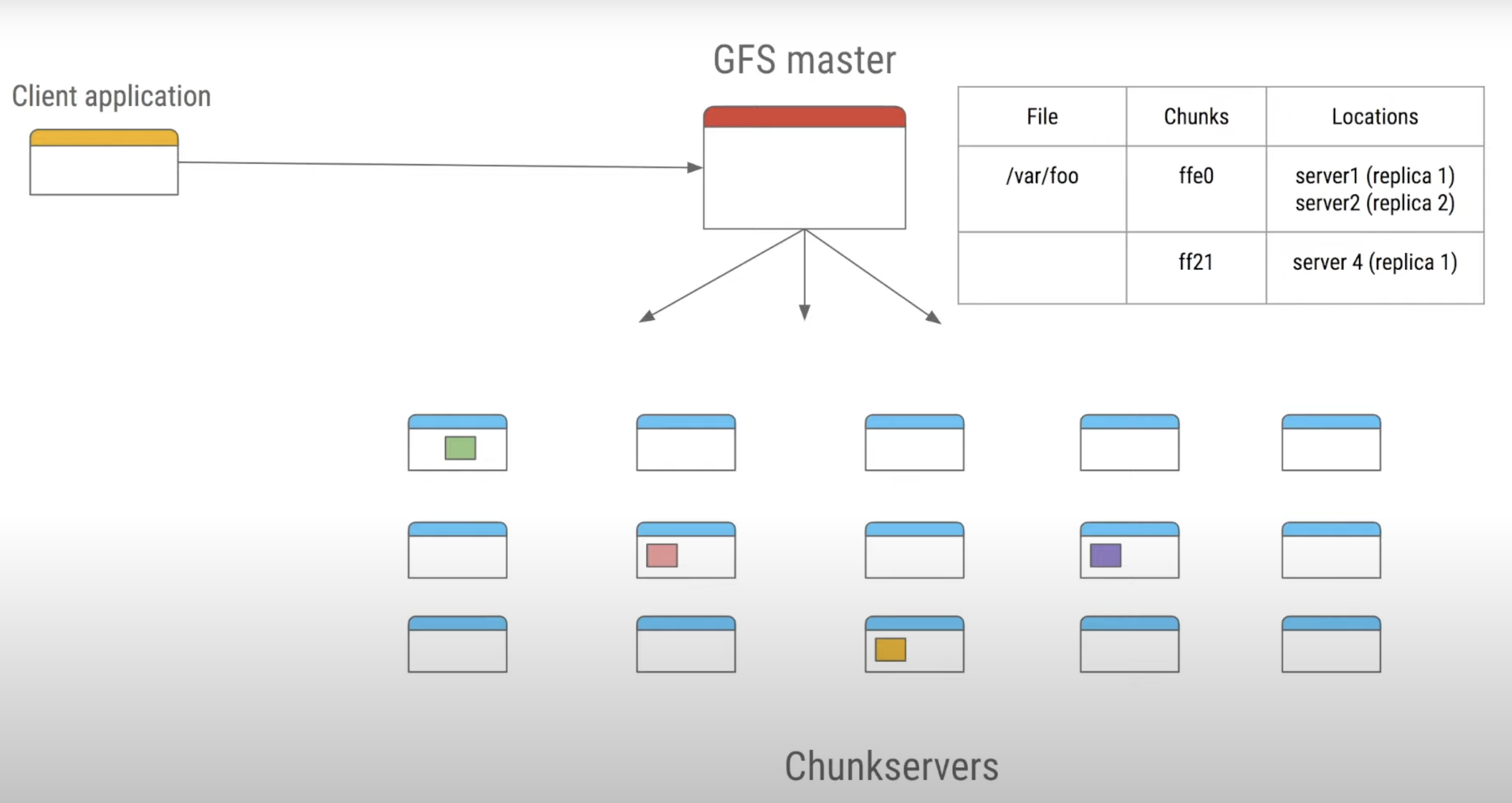
Architecture
clients (library, RPC -- but not visible as a UNIX FS)
coordinator tracks file names
chunkservers store 64 MB chunks
big files split into 64 MB chunks, on lots of chunkservers
big chunks -> low book-keeping overhead
each chunk replicated on 3 chunkservers
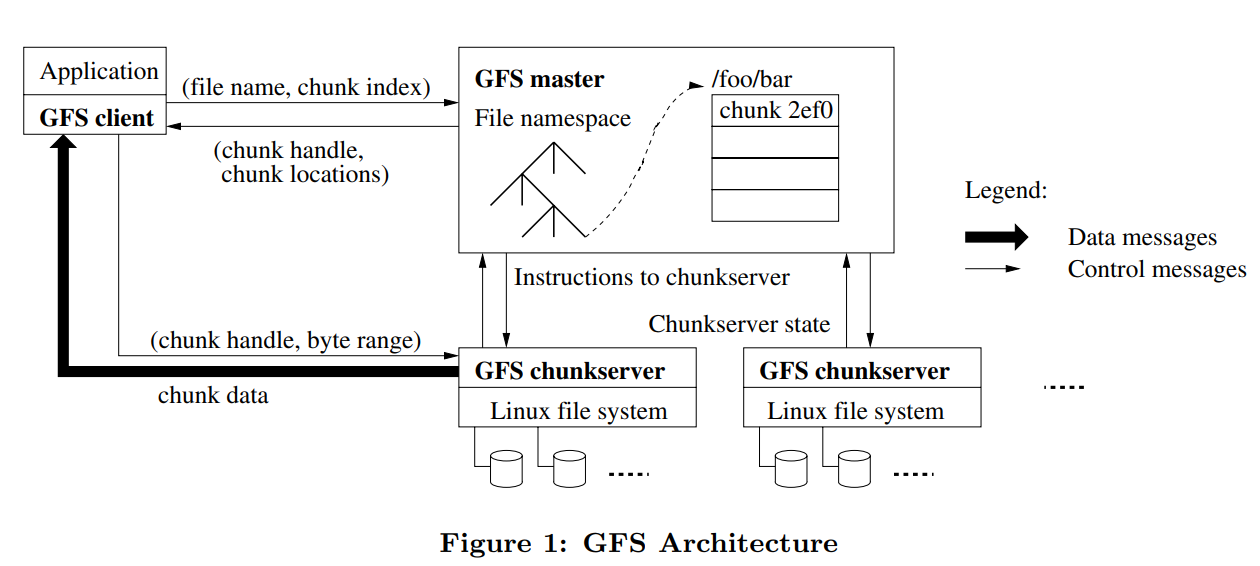
- GFS consists of a single master and multiple chunkservers and is accessed by multiple clients.
- Files are divided into fixed-sized chunks of 64MB.
- Each chunk has an immutable and globally unique chunk handler, which is assigned by the master at the time of chunk creation.
- By default, each file chunk is replicated on 3 different chunkservers.
Analogy with File system
On a single-machine FS:
- An upper layer maintains the metadata.
- A lower layer (i.e. disk) stores the data in units called “blocks”.
- Upper layer store
In the GFS:
- A master process maintains the metadata.
- A lower layer (i.e. a set of chunkservers) stores the data in units called “chunks”.
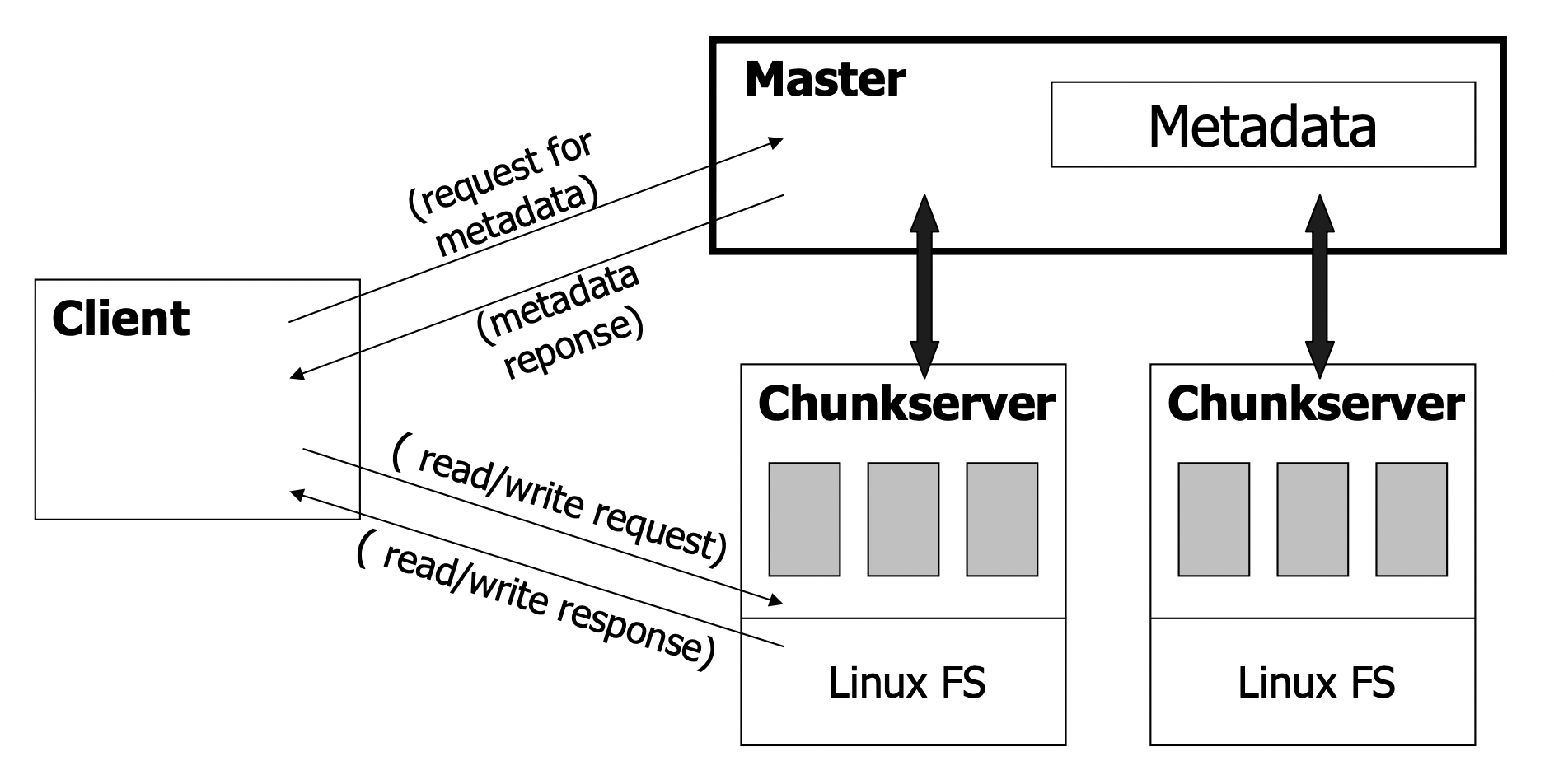
Very important: data flow is decoupled from control flow
- Clients interact with the master for metadata operations
- Clients interact directly with chunkservers for all files operations
- This means performance can be improved by scheduling expensive data flow based on the network topology
Neither the clients nor the chunkservers cache file data
- Working sets are usually too large to be cached, chunkservers can use Linux’s buffer cache
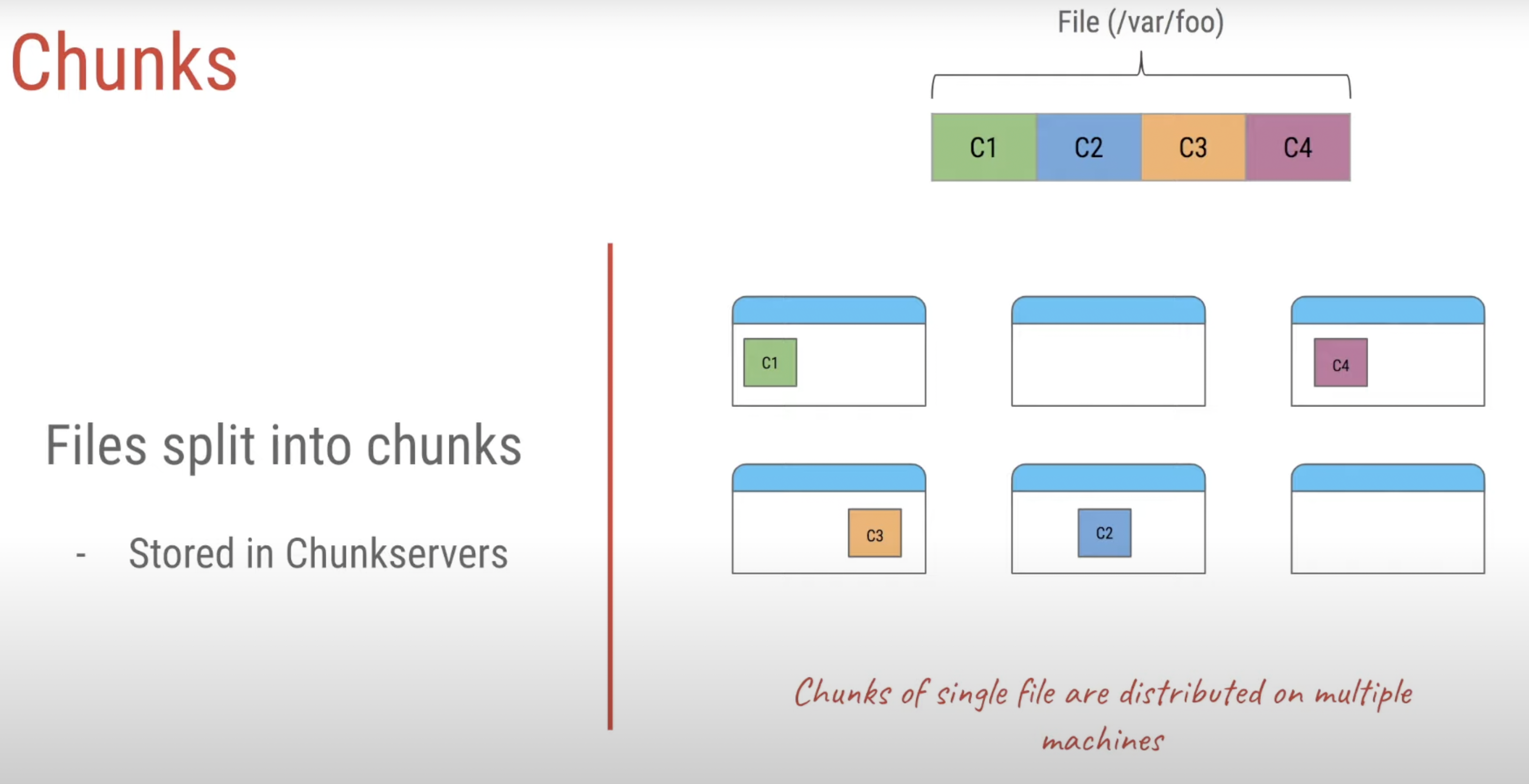
What is a chunk?
- Analogous to block, except larger.
- Size: 64 MB!
- Stored on chunkserver as file
- Chunk handle (~ chunk file name) used to reference chunk.
- Chunk replicated across multiple chunkservers
- Note: There are hundreds of chunkservers in a GFS cluster distributed over multiple racks.
What is a master?
- A single process running on a separate machine.
- Stores all metadata:
- File namespace
- File to chunk mappings
- Chunk location information
- Access control information
- Chunk version numbers
Coordinator(Master) state
tables in RAM (for speed, must be smallish):
file name -> array of chunk handles (nv)
chunk handle -> version # (nv)
list of chunkservers (v)
primary (v)
lease time (v)
non-volatile "nv" state also written to disk, in case crash+reboot
The Master Node
- Responsible for all system-wide activities
- managing chunk leases, reclaiming storage space, load-balancing
- Maintains all file system metadata
- Namespaces, ACLs, mappings from files to chunks, and current locations of chunks
- all kept in memory, namespaces and file-to-chunk mappings are also stored persistently in operation log
- Periodically communicates with each chunkserver in HeartBeat messages
- This let’s master determines chunk locations and assesses state of the overall system
- Important: The chunkserver has the final word over what chunks it does or does not have on its own disks – not the master
- For the namespace metadata, master does not use any per-directory data structures – no inodes! (No symlinks or hard links, either.)
- Every file and directory is represented as a node in a lookup table, mapping pathnames to metadata. Stored efficiently using prefix compression (< 64 bytes per namespace entry)
- Each node in the namespace tree has a corresponding read-write lock to manage concurrency
- Because all metadata is stored in memory, the master can efficiently scan the entire state of the system periodically in the background
- Master’s memory capacity does not limit the size of the system
The Operation Log
- Only persistent record of metadata
- Also serves as a logical timeline that defines the serialized order of concurrent operations
- Master recovers its state by replaying the operation log
- To minimize startup time, the master checkpoints the log periodically
- The checkpoint is represented in a B-tree like form, can be directly mapped into memory, but stored on disk
- Checkpoints are created without delaying incoming requests to master, can be created in ~1 minute for a cluster with a few million files
- To minimize startup time, the master checkpoints the log periodically
Interface
- GFS does not provide a file system interface at the operating-system level (e.g., under the VFS layer). As such, file system calls are not used to access it. Instead, a user-level API is provided. GFS is implemented as a set of user-level services that store data onto native Linux file systems.
- Moreover, since GFS was designed with special considerations in mind, it does not support all the features of POSIX (Linux, UNIX, OS X, BSD) file system access.
- It provides a familiar interface of files organized in directories with basic create, delete, open, close, read, and write operations.
- In addition, two special operations are supported.
- A snapshot is an efficient way of creating a copy of the current instance of a file or directory tree.
- An append operation allows a client to append data to a file as an atomic operation without having to lock a file. Multiple processes can append to the same file concurrently without fear of overwriting one another’s data.
Configuration
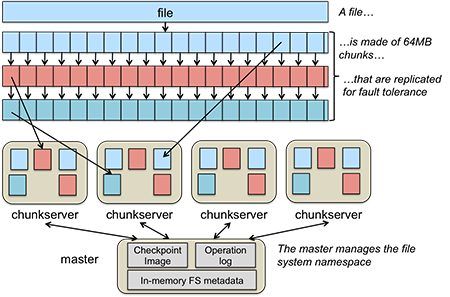
GFS data chunking and distribution
- A file in GFS is broken up into multiple fixed-size chunks. Each chunk is 64 MB.
- The set of machines that implements an instance of GFS is called a GFS cluster.
- A GFS cluster consists of one master and many chunkservers.
- The master is responsible for storing all the metadata for the files in GFS. This includes their names, directories, and the mapping of files to the list of chunks that contain each file’s data.
- The chunks themselves are stored on the chunkservers. For fault tolerance, chunks are replicated onto multiple systems.
The following figure shows how a file is broken into chunks and distributed among multiple chunkservers.
Google Cluster Environment
- The Google File System is a core part of the Google Cluster Environment.
- This environment has GFS and a cluster scheduling system for dispatching processes as its core services.
- Typically, hundreds to thousands of active jobs are run. Over 200 clusters are deployed, many with thousands of machines. P
- ools of thousands of clients access the files in this cluster.
- The file systems exceed four petabytes and provide reaa/write loads of 40 GB/s. Jobs are often on the same machines that implement GFS, which are commodity PCs running Linux.
The environment is shown in following figure.
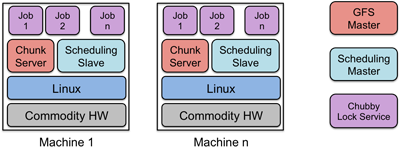
Ref: https://pk.org/417/notes/16-dfs.html
Client interaction model
- Since the GFS client is not implemented in the operating system at the VFS layer, GFS client code is linked into each application that uses GFS.
- This library interacts with the GFS master for all metadata-related operations (looking up files, creating them, deleting them, etc.).
- For accessing data, it interacts directly with the chunkservers that hold that data.
- This way, the master is not a point of congestion. Except for caching within the buffer cache on the chunkservers, neither clients nor chunkservers cache a file’s data.
- However, client programs do cache the metadata for an open file (for example, the location of a file’s chunks).
- This avoids additional traffic to the master.
Implementation
Each chunkserver stores chunks. A chunk is identified by a chunk handle, which is a globally unique 64-bit number that is assigned by the master when the chunk is first created. On the chunkserver, every chunk is stored on the local disk as a regular Linux file. For integrity, the chunkserver stores a 32-bit checksum for each chunk (and logged to disk) for each chunk on that chunkserver.
Every chunk is replicated onto multiple chunkservers. By default, there are three replicas of a chunk althrough different levels can be specified on a per-file basis. Files that are accessed by lots of processes may need more replicas to avoid congestion at any server.
Master
The primary role of the master is to maintain all of the file system metadata. This include the names and directories of each file, access control information, the mapping from each file to a set of chunks, and the current location of chunks on chunkservers. Metadata is stored only on the master. This simplifies the design of GFS as there is no need to handle synchronizing information for a changing file system among multiple masters.
For fast performance, all metadata is stored in the master’s main memory. This includes the entire filesystem namespace as well as all the name-to-chunk maps. For fault tolerance, any changes are written to the disk onto an operation log. This operation log is also replicated onto remote machines. The operation log is similar to a journal. Every operation to the file system is logged into this file. Periodic checkpoints of the file system state, stored in a B-tree structure, are performed to avoid having to recreate all metadata by playing back the entire log.
Having a single master for a huge file system sounds like a bottleneck but the role of the master is only to tell clients which chunkservers to use. The data access itself is handled between the clients and chunkservers.
The file system namespace of directories and file names is maintained by the master. Unlike most file systems, there is no separate directory structure that contains the names of all the files within that directory. The namespace is simply a single lookup table that contains pathnames (which can look like a directory hierarchy if desired) and maps them to metadata. GFS does not support hard links or symbolic links.
The master manages chunk leases (locks on chunks with expiration), garbage collection (the freeing of unused chunks), and chunk migration (the movement and copying of chunks to different chunkservers). It periodically communicates with all chunkservers via heartbeat messages to get the state of chunkservers and sends commands to chunkservers. The master does not store chunk locations persistently on its disk. This information is obtained from queries to chunkservers and is done to keep consistency problems from arising.
The master is a single point of failure in GFS and replicates its data onto backup masters for fault tolerance.
Chunk size
- The default chunk size in GFS is 64MB, which is a lot bigger than block sizes in normal file systems (which are often around 4KB).
- Small chunk sizes would not make a lot of sense for a file system designed to handle huge files since each file would then have a map of a huge number of chunks. This would greatly increase the amount of data a master would need to manage and increase the amount of data that would need to be communicated to a client, resulting in extra network traffic.
- A master stores less than 64 bytes of metadata for each 64MB chunk. By using a large chunk size, we reduce the need for frequent communication with the master to get chunk location information.
- It becomes feasible for a client to cache all the information related to where the data of large files is located.
- To reduce the risk of caching stale data, client metadata caches have timeouts.
- A large chunk size also makes it feasible to keep a TCP connection open to a chunkserver for an extended time, amortizing the time of setting up a TCP connection.
File access
To read a file, the client contacts the master to read a file’s metadata; specifically, to get the list of chunk handles. It then gets the location of each of the chunk handles. Since chunks are replicated, each chunk handle is associated with a list of chunkservers. The client can contact any available chunkserver to read chunk data.
File writes are expected to be far less frequent than file reads. To write to a file, the master grants a chunk lease to one of the replicas. This replica will be the primary replica chunkserver and will be the first one to get updates from clients. The primary can request lease extensions if needed. When the master grants the lease, it increments the chunk version number and informs all of the replicas containing that chunk of the new version number.
The actual writing of data is split into two phases: sending and writing.
First, the client is given a list of replicas that identifies the primary chunkserver and secondaries. The client sends the data to the closest replica chunkserver. That replica forwards the data to another replica chunkserver, which then forwards it to yet another replica, and so on. Eventually all the replicas get the data, which is not yet written to a file but sits in a cache.
When the client gets an acknowledgement from all replicas that the data has been received it then sends a write request to the primary, identifying the data that was sent in the previous phase. The primary is responsible for serialization of writes. It assigns consecutive serial numbers to all write requests that it has received, applies the writes to the file in serial-number order, and forwards the write requests in that order to the secondaries. Once the primary gets acknowledgements from all the secondaries, the primary responds back to the client and the write operation is complete.
The key point to note is that data flow is different from control flow. The data flows from the client to a chunkserver and then from that chunkserver to another chunkserver, and from that other chunkserver to yet another one until all chunkservers that store replicas for that chunk have received the data. The control (the write request) flow goes from the client to the primary chunkserver for that chunk. The primary then forwards the request to all the secondaries. This ensures that the primary is in control of the order of writes even if it receives multiple write requests concurrently. All replicas will have data written in the same sequence. Chunk version numbers are used to detect if any replica has stale data that was not updated because that chunkserver was down during some update.
Hadoop Distributed File System (HDFS)
File system operations
The Hadoop Distributed File System is inspired by GFS. The overall architecture is the same, although some terminology changes.

- The file system provides a familiar file system interface. Files and directories can be created, deleted, renamed, and moved and symbolic links can be created.
- However, there is no goal of providing the rich set of features available through, say, a POSIX (Linux/BSD/OS X/Unix) or Windows interface. That is, synchronous I/O, byte-range locking, seek-and-modify, and a host of other features may not be supported.
- Moreover, the file system is provided through a set of user-level libraries and not as a kernel module under VFS. Applications have to be compiled to incorporate these libraries.
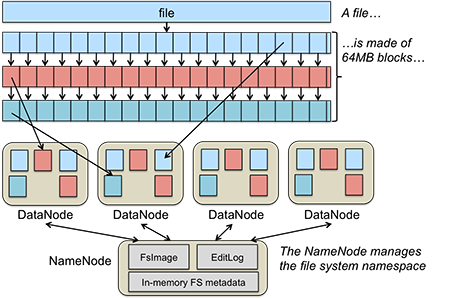
- A file is made up of equal-size data blocks, except for the last block of the file, which may be smaller. These data blocks are stored on a collection of servers called DataNodes.
- Each block of a file may be replicated on multiple DataNodes for high availability. The block size and replication factor is configurable per file. DataNodes are responsible for storing blocks, handling read/write requests, allocating and deleting blocks, and accepting commands to replicate blocks on another DataNode.
- A single NameNode is responsible for managing the name space of the file system and coordinating file access. It stores keeps track of which block numbers belong to which file and implements open, close, rename, and move operations on files and directories.
- All knowledge of files and directories resides in the NameNode.
Heartbeating and Replication
DataNodes periodically send a heartbeat message and a block report to the NameNode.
- The heartbeat informs the NameNode that the DataNode is functioning.
- The block report contains a list of all the blocks on that DataNode. A block is considered safely replicated if the minimum number of replica blocks have been sent by block reports from all available DataNodes.
The NameNode waits for a configured percentage of DataNodes to check in and then waits an additional 30 seconds. After that time, if any data blocks do not have their minimum number of replicas, the NameNode sends replica requests to DataNodes, asking them to create replicas of specific blocks.
- The system is designed to be rack-aware and data center-aware in order to improve availability and performance. What this means is that the NameNode knows which DataNodes occupy the same rack and which racks are in one data center.
- For performance, it is desirable to have a replica of a data block in the same rack. For availability, it is desirable to have a replica on a different rack (in case the entire rack goes down) or even in a different data center (in case the entire data center fails).
- HDFS supports a pluggable interface to support custom algorithms that decide on replica placement. In the default case of three replicas, the first replica goes to the local rack and both the second and third replicas go to the same remote rack.

The NameNode chooses a list of DataNodes that will host replicas of each block of a file. A client writes directly to the first replica. As the first replica gets the data from the client, it sends it to the second replica even before the entire block is written (e.g., it may get 4 KB out of a 64 MB block). As the second replica gets the data, it sends it to the third replica
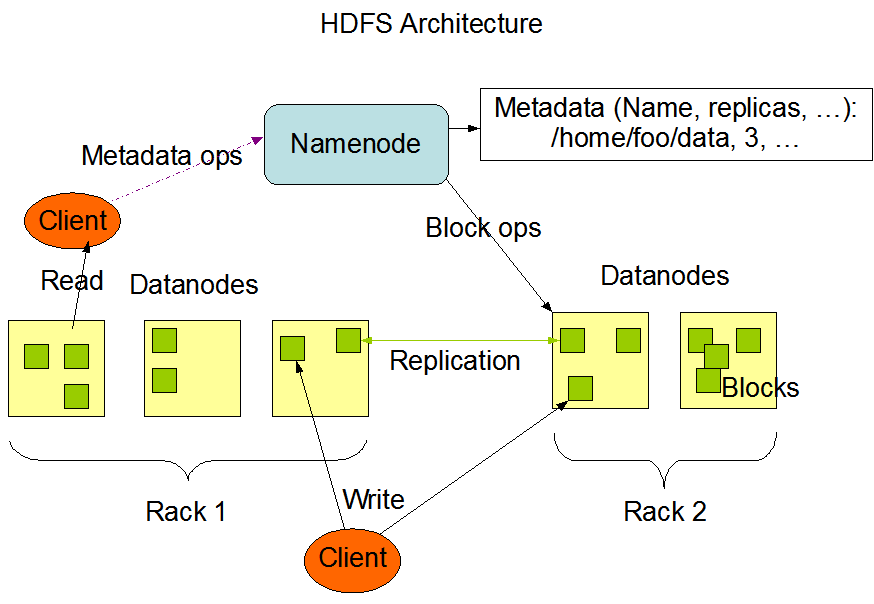
Implementation
The NameNode contains two files: EditLog and FsInfo.
- The EditLog is a persistent record of changes to any HDFS metadata (file creation, addition of new blocks to files, file deletion, changes in replication, etc.). It is stored as a file on the server’s native file system.
- The FsInfo file stores the entire file system namespace. This includes file names, their location in directories, block mapping for each file, and file attributes. This is also stored as a file on the server’s native file system.
The entire active file system image is kept in memory. On startup, the NameNode reads FsInfo and applies the list of changes in EditLog to create an up-to-date file system image. Then, the image is flushed to the disk and the EditLog is cleared. This sequence is called a checkpoint. From this point, changes to file system metadata are logged to EditLog but FsInfo is not modified until the next checkpoint.
On DataNodes, each block is stored as a separate file in the local file system. The DataNode does not have any knowledge of file names, attributes, and associated blocks; all that is handled by the NameNode. It simply processes requests to create, delete, write, read blocks, or replicate blocks. Any use of directories is done strictly for local efficiency - to ensure that a directory does not end up with a huge number of files that will impact performance.
To ensure data integrity, each HDFS file has a separate checksum file associated with it. This file is created by the client when the client creates the data file/. Upon retrieval, if there is a mismatch between the block checksum and the computed block checksum, the client can request a read from another DataNode.
Summary
How GFS is Different From Other Distributed FS’s
Based on Google’s workload, GFS assumes
- High failure rate
- Huge files (optimized for GB+ files)
- Almost all writes are appends
- Reads are either small and random OR big and streaming
- There’s no need to implement POSIX (no symbolic links, etc.)
- Throughput is more important than latency
Ref
-
Sanjay Ghemawat, Howard Gobioff, and Shun-Tak Leung, The Google File System. Google, SOSP’03, October 19–22, 2003.
-
Google File System, Wikipedia article.
-
HDFS Architecture Guide, Apache Hadoop project, December 4, 2011.
-
https://melodiessim.netlify.app/gfs-summary/
-
https://liyafu.com/2021-10-22-how-gfs-works/