MapReduce
A framework for large-scale parallel processing.
Goal: Create a distributed computing framework to process data on a massive scale.
MapReduce is a software framework for processing (large) data sets in a distributed fashion over a several machines.
MapReduce = high-level programming model and implementation for large-scale parallel data processing
MapReduce framework/library allows programmers without any experience with parallel and distributed systems to easily utilize the resources of a large distributed system.
- A big goal: easy for non-specialist programmers
- programmer just defines Map and Reduce functions, often simple sequential code
- MR manages, and hides, all aspects of distribution!
- MR is a framework / library; “application” is just Map()/Reduce()
Motivation
Context: multi-hour computations on multi-terabyte data-sets e.g. build search index, or sort, or analyze structure of web only practical with 1000s of computers
- Inverted index is storing a mapping from content, such as words or numbers, to its documents where the word is present on the web. Indexing is the process by which search engines organize information before a search to enable super-fast responses to queries.
- To index
20+billion web pages, assuming each is of20KBsize, we need to process400+terabytes of data.20+billion web pagesx 20KB=400+terabytes- One computer can read
30-35 MB/secfrom disk, so it takes four months to read the web ~1,000hard drives just to store the web- Good news: same problem with
1000machines,< 3hours
- Most such computations are conceptually straightforward. However, the input data is usually large and the computations have to be distributed across hundreds or thousands of machines in order to finish in a reasonable amount of time.
- But to solve the problem on
1000machines, we will need to write programs to handle- communication and coordination: parallelize the computation and distribute the data
- handle failures and recovering from machine failure (all the time!)
- status reporting, debugging, optimization and locality
-
Similar difficulty repeats for every problem Google wants to solve
- As a reaction to this complexity, Google designed an abstraction that allows us to express the simple computations we were trying to perform but hides the messy details in MapReduce runtime library:
- automatic parallelization
- load balancing
- data distribution: network and disk transfer optimization
- fault tolerance: handling of machine failures and robustness
- improvements to core library benefit all users of library!
MapReduce Etymology
- MapReduce was created at Google in 2004 by Jeffrey Dean and Sanjay Ghemawat.
- The name is inspired from map and reduce functions in the LISP programming language.
- In LISP, the map function takes as parameters a function and a set of values. That function is then applied to each of the values.
- length function to each item
(map ‘length ‘(() (a) (ab) (abc)))to(0 1 2 3)
- length function to each item
- The reduce function is given a binary function and a set of values as parameters. It combines all the values together using the binary function.
- add function in reduce
(reduce #'+ '(0 1 2 3))to6
- add function in reduce
Programming Model
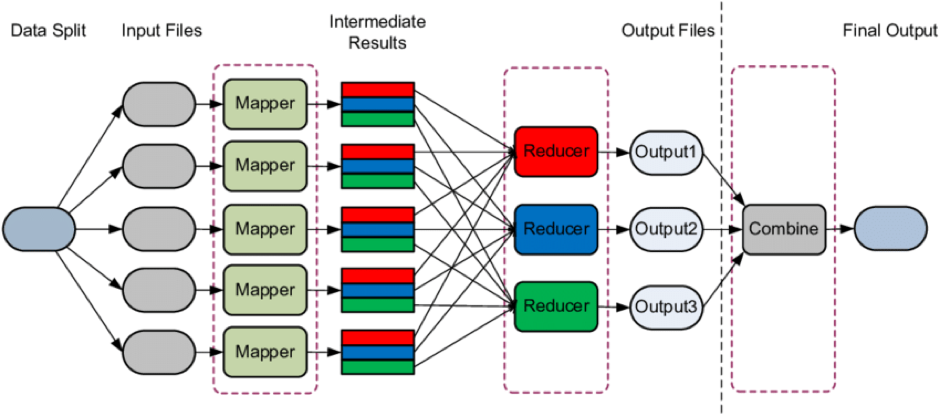
- The computation takes a set of input key/value pairs, and produces a set of output key/value pairs.
- The user of the MapReduce library expresses the computation as two functions: Map and Reduce.
- Map, written by the user, takes an input pair and produces a set of intermediate key/value pairs.
- The MapReduce library groups together all intermediate values associated with the same intermediate key I and passes them to the Reduce function.
- The Reduce function, also written by the user, accepts an intermediate key I and a set of values for that key. It merges together these values to form a possibly smaller set of values.
map (k1,v1) → list(k2,v2)
reduce (k2,list(v2)) → list(v2)
Programmer specifies two primary methods:
- Map:
(k, v) ↦ <(k1,v1), (k2,v2), (k3,v3),…,(kn,vn)> - Reduce:
(k', <v’1, v’2,…,v’m>) ↦ <(k', v'’1), (k', v'’2),…,(k', v'’k)>
All v' with same k' are reduced together. (Remember the invisible “Shuffle and Sort” step).
Word-count example
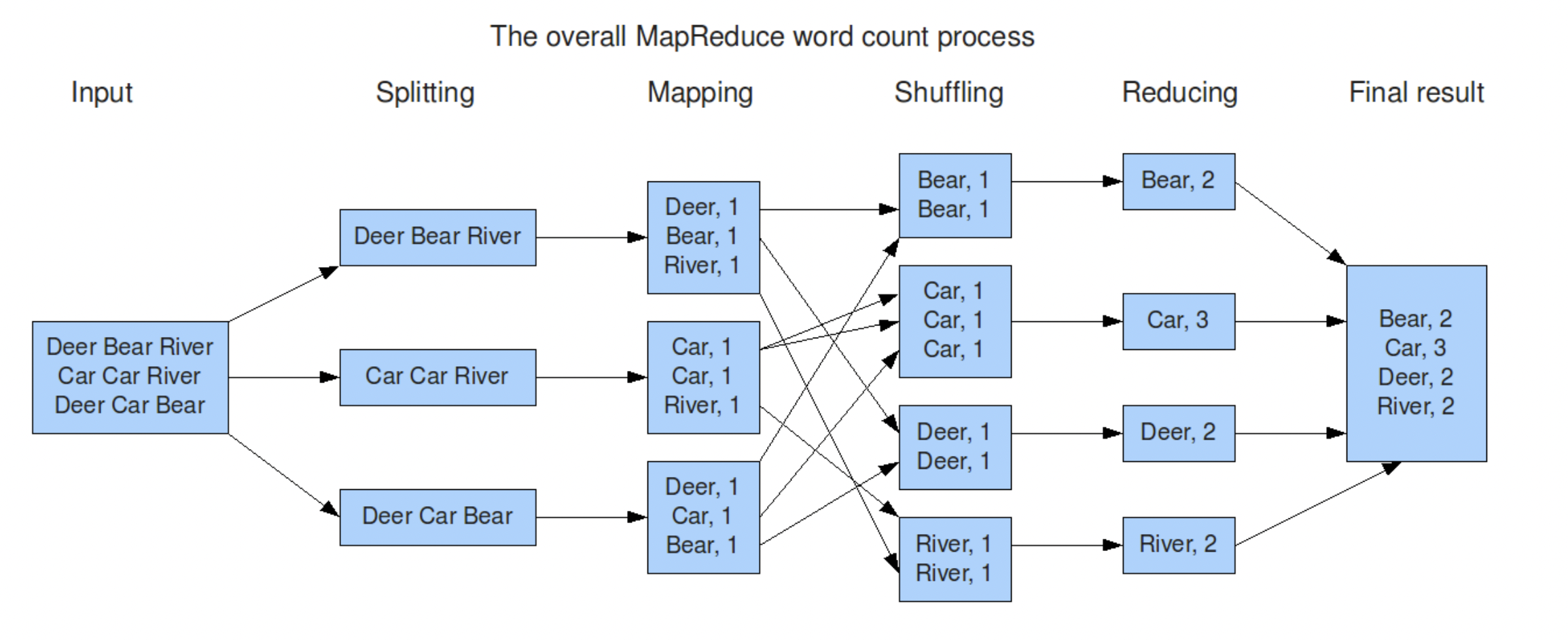
Counting the number of occurrences of each word in a large collection of documents.
- The map function emits each word plus an associated count of occurrences (just ‘1’ in this simple example).
- The reduce function sums together all counts emitted for a particular word.
Input1 -> Map -> a,1 b,1
Input2 -> Map -> b,1
Input3 -> Map -> a,1 c,1
| | |
| | -> Reduce -> c,1
| -----> Reduce -> b,2
---------> Reduce -> a,2
Abstract view of a MapReduce job – word count
1) input is (already) split into M pieces
2) MR calls Map() for each input split, produces list of k,v pairs
“intermediate” data
each Map() call is a “task”
3) when Maps are done,
MR gathers all intermediate v’s for each k,
and passes each key + values to a Reduce call
4) final output is set of <k,v> pairs from Reduce()s
Word-count code
Map(d)
chop d into words
for each word w
emit(w, "1")
Reduce(k, v[])
emit(len(v[]))
More details
Ref: https://web.stanford.edu/class/archive/cs/cs110/cs110.1204/static/lectures/cs110-lecture-17-mapreduce.pdf
Other examples
Map Reduce Notes
Data Storage
Data Model
Map Phase
Reduce Phase
Execution Overview
Ref: http://www.cohenwang.com/edith/bigdataclass2013/lectures/MapReduce_Kryzanowski.pdf
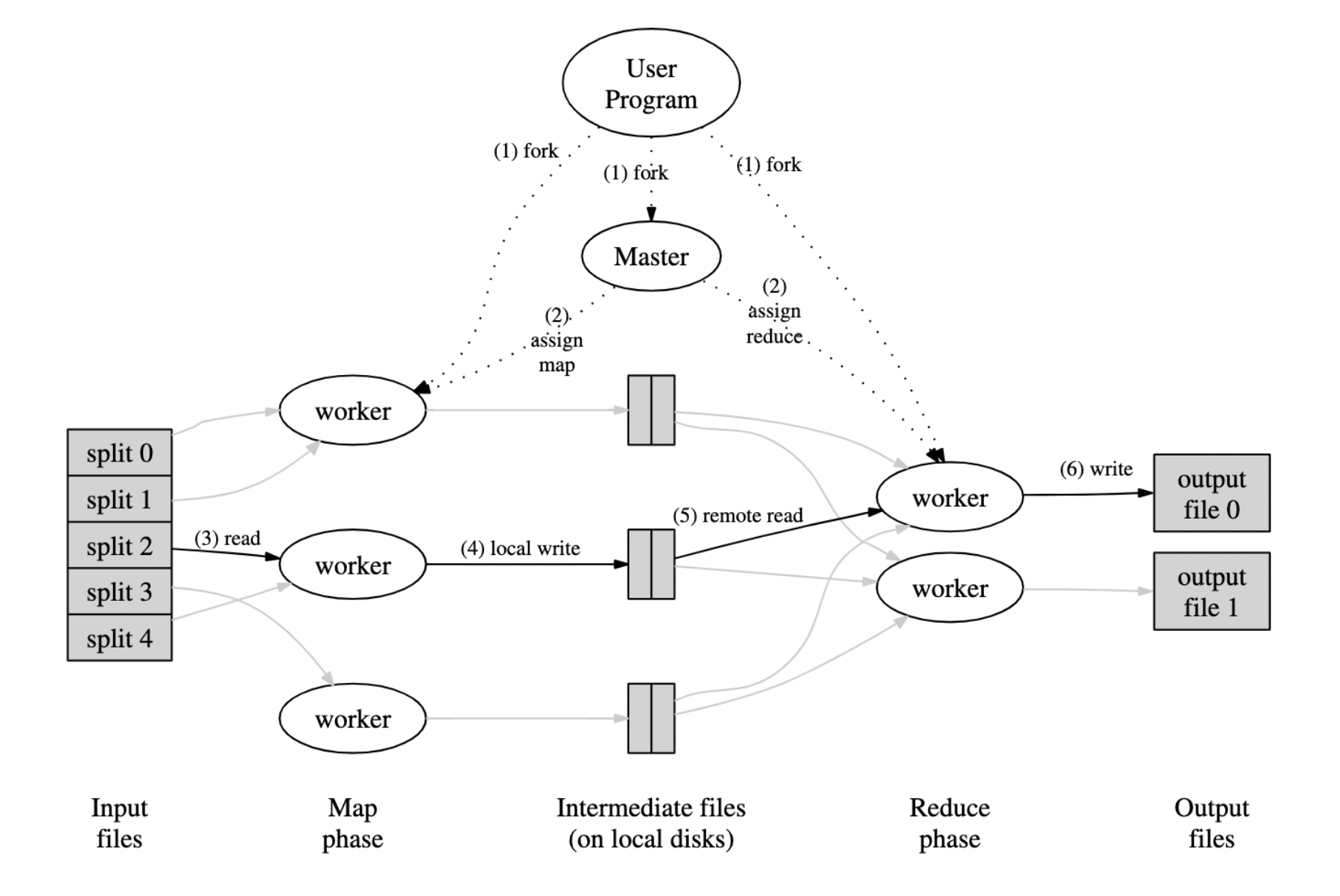
One master, many workers
- Input data split into M map tasks (typically 64 MB in size)
- Reduce phase partitioned into R reduce tasks (= # of output files)
- Tasks are assigned to workers dynamically
- Reasonable numbers inside Google: M=200,000; R=4,000; workers=2,000
Master assigns each map task to a free worker
- Considers locality of data to worker when assigning task
- Worker reads task input (often from local disk!)
- Worker produces R local files containing intermediate (k,v) pairs
Master assigns each reduce task to a free worker
- Worker reads intermediate (k,v) pairs from map workers
- Worker sorts & applies user’s Reduce op to produce the output
- User may specify Partition: which intermediate keys to which Reducers
Input and output are stored on the GFS cluster file system
- MR needs huge parallel input and output throughput.
- GFS splits files over many servers, many disks, in 64 MB chunks
- Maps read in parallel
- Reduces write in parallel
- GFS replicates data on 2 or 3 servers, for fault tolerance
- GFS is a big win for MapReduce
Scalability
MapReduce scales well:
- N “worker” computers (might) get you Nx throughput.
- Maps()s can run in parallel, since they don’t interact.
- Same for Reduce()s.
- Thus more computers -> more throughput – very nice!
MapReduce hides much complexity:
- sending map+reduce code to servers
- tracking which tasks have finished
- “shuffling” intermediate data from Maps to Reduces
- balancing load over servers
- recovering from crashed servers
To get these benefits, MapReduce restricts applications:
- Only one pattern (Map -> shuffle -> Reduce).
- No interaction or state (other than via intermediate output).
- Only batch: no real-time or streaming processing.
Ref: https://static.googleusercontent.com/media/research.google.com/en//pubs/archive/32721.pdf
MR writes Map() output to local disk
- MR splits into files by hash(key) mod R
- each “hash bucket” contains multiple keys
- The map workers all hash the same way
The shuffle
- each Reduce task processes one hash bucket
- MR fetches each Reduce tasks’ bucket from every Map worker
- merge, sort by key, call Reduce() for each key
- each Reduce task writes a separate output file on GFS
The “Coordinator” manages all the steps in a job.
- tracks state of each task
- hands out tasks to worker machines
MapReduce Granularity
Fine granularity tasks: many more map tasks than machines
- Minimizes time for fault recovery
- Can pipeline shuffling with map execution
- Better dynamic load balancing
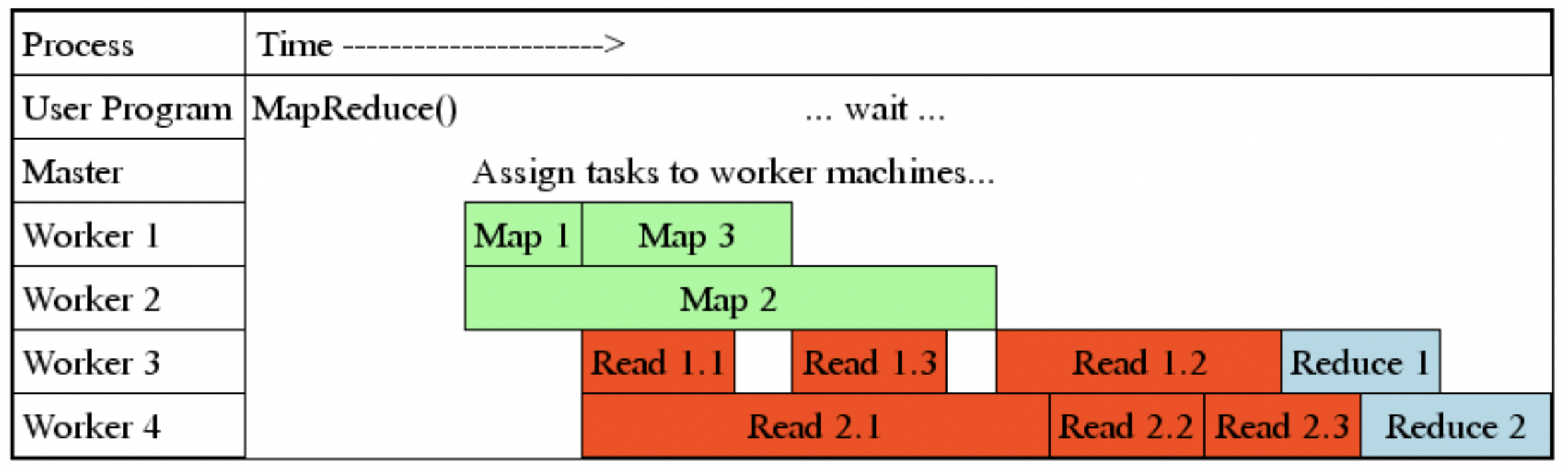
Skew
Straggler
MapReduce: Fault Tolerance via Re-Execution
Worker failure:
- Detect failure via periodic heartbeats
- Re-execute completed and in-progress map tasks
- Re-execute in-progress reduce tasks
- Task completion committed through master
Master failure:
- State is checkpointed to replicated file system
- New master recovers & continues
Very Robust: lost 1600 of 1800 machines once, but finished fine
Typical problem solved by MapReduce
- Read a lot of data
- Map: extract something you care about from each record
- Shuffle and Sort
- Reduce: aggregate, summarize, filter, or transform
- Write the results
Outline stays the same, Map and Reduce functions change to fit the problem
Not used much currently
- Batch Only: MapReduce is strictly for “batch” (looking at old data). It cannot handle real-time streaming, whereas newer tools handle both.
- Disk-Heavy Performance: MapReduce writes data to the physical disk after every single step. This makes it incredibly slow for complex jobs. Modern engines use In-Memory processing, which is significantly faster.
Every modern distributed system mentioned—Spark, Snowflake, and BigQuery—is essentially a more refined, faster evolution of the core ideas MapReduce pioneered:
- Divide and Conquer: Breaking a big task into tiny pieces.
- Locality: Bringing the computation to where the data lives, rather than moving the data.
Reference:
- MapReduce: Simplified Data Processing on Large Clusters by Jeffrey Dean and Sanjay Ghemawat
- The MapReduce Paradigm by Michael Kleber, Jan. 14, 2008