ZooKeeper
“Because coordinating distributed systems is a Zoo”
Guarantees:
ZooKeeper’s performance can scale linearly through the guarantees it provides.
Clients requests are processed in FIFO order, this is per client for Reads
Let’s consider the distributed key-value store shown below which makes use of a Raft module in each replica.
- All the writes in Raft must go through a leader.
- To guarantee a linearizable history, all reads must go through the leader as well.
- One reason why reads cannot be sent to followers is that a replica may not be in the majority needed by Raft, and so may return stale value which violates linearizability.
In a Raft based system, adding more servers will likely degrade the performance of the system. This is because all the reads must still go through the leader, and the leader now has to store more information about the new servers.
ZooKeeper, on the other hand, allows us to scale the performance of our system linearly by adding more servers. It does this by relaxing the definition of correctness and providing weaker guarantees for clients.
Reads can be served from any replica but writes are still sent to a leader. While this has the downside that reads may return stale data, it greatly improves the performance of reads in the system. ZooKeeper is a system designed for read-heavy workloads, and so the trade-off that leads to better read performance is worth it.
Zookeeper vs RAFT
- ZooKeeper is a distributed coordination service;
- Zookeeper uses ZooKeeper Atomic Broadcast(ZAB).
- ZAB was born in 2007 along with Zookeeper. The Raft protocol had not been developed that time
- Raft is a consensus protocol(It is not something you “run”; it is something you implement inside a system to make it fault-tolerant).
ZAB
Background
- Developed at Yahoo! Research
- Started as sub-project of Hadoop, now a top-level Apache project
- Development is driven by application needs
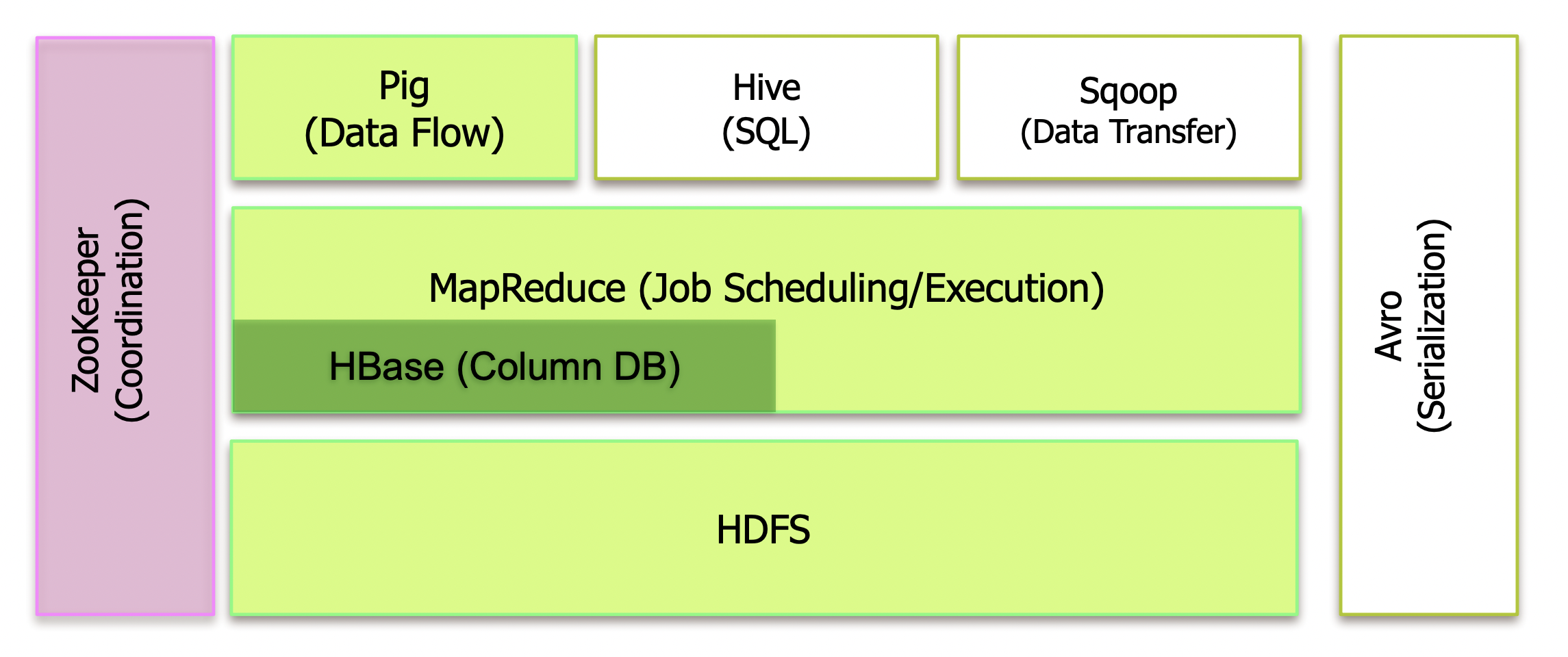
ZooKeeper in the Hadoop ecosystem
Motivation
- In the past: a single program running on a single computer with a single CPU
- Today: applications consist of independent programs running on a changing set of computers
- Difficulty: coordination of those independent programs
- Developers have to deal with coordination logic and application logic at the same time
ZooKeeper: designed to relieve developers from writing coordination logic code.
A centralized service for maintaining configuration information, naming, providing distributed synchronization, and providing group services
- Distributed, Consistent Data Store - Some servers might be eventually consistent (see the sync api)
- Highly Available
- High performance
- Strictly ordered access
Highly Available
Tolerates the loss of a minority of ensemble members and still function.
- As long as a majority of the servers are available, the ZooKeeper service will be available.
- To tolerate a loss of
nmembers, we need atleast2 * n + 1nodes(that is there should ben + 1nodes available as majority) because fornto be the minority, we need atleast2 * n + 1nodes. - Its good to form an Ensemble of odd number of nodes - as
n(even number) nodes tends to allow same number of failure as ofn - 1(odd number) nodes. - It’s recommended to have odd number(3 or 5) of nodes because we want to have majority surviving to continue to function, You don’t get any benefit by having 6 nodes instead of 5 nodes, for both 5 or 6 nodes, we can only have loss of 2 nodes.
One more way of looking at this odd number majority scheme is that, when there is a partition, there can’t be more than one partition with majority of servers in it.
High Performance
- All data is stored in memory
- Performance measured around 50,000 operations/second
- Particularly fast for read performance, built for read dominant workloads
Strictly ordered access
- Atomic Writes
- In the order you sent them
- Changes always seen in the order they occurred
- Reliable, no writes acked will be dropped
Basic Cluster Interactions
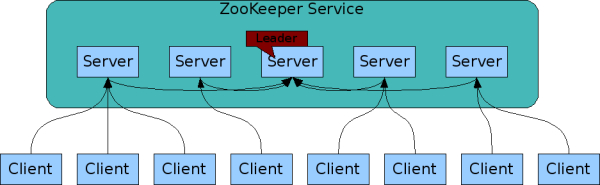
- ZooKeeper is replicated. Like the distributed processes it coordinates, ZooKeeper itself is intended to be replicated over a sets of hosts called an ensemble.
- ZooKeeper service is an ensemble of servers that use replication (high availability)
- During startup, When a leader doesn’t exist in the ensemble, ZooKeeper runs a leader election algorithm in the ensemble of servers.
- One leader and remaining all followers.
- Clients connect to a single ZooKeeper server. The client maintains a TCP connection through which it sends requests, gets responses, gets watch events, and sends heart beats. If the TCP connection to the server breaks, the client will connect to a different server.
- Can read from any ZooKeeper server
- Writes go through the leader & need majority consensus
When one server goes down, clients will see a disconnect event and client will re-connect themselves to another member of the quorum.
One more thing with 2 * n + 1 servers is that, any two majorities will have atleast one overlap server. Because there are atleast n + 1 in the majority, there is intersection with atleast one server from the previous majority.
Zookeeper data structure
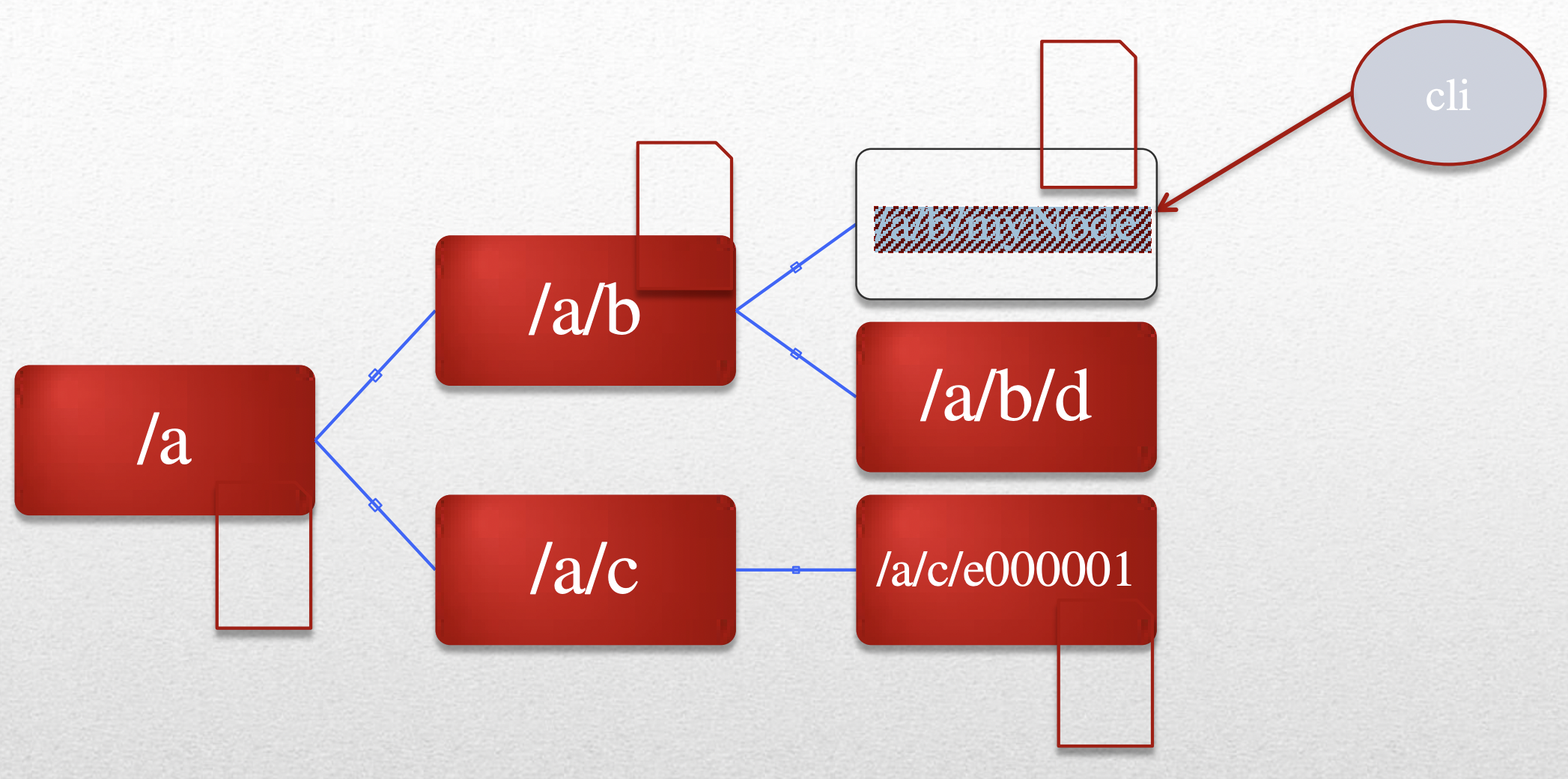
- Nodes can contain data, have children, or both. Every node in a zookeper tree is called a znode.
- znode: in-memory data node in ZooKeeper, organised in a hierarchical namespace (the data tree)
- Types of Znode
- Regular node: Clients create and delete explicitly
- Ephemeral nodes are associated with the session that created them.
- Like regular znodes but associated with sessions
- These nodes exists as long as the session that created the znode is active. When the session ends the znode is deleted.
- They cannot have children, and disappear when that session ends
- Sequential nodes have an ever-increasing number attached to them
- Property of regular and ephemeral znodes
- Has a universal, monotonically increasing counter appended to the name
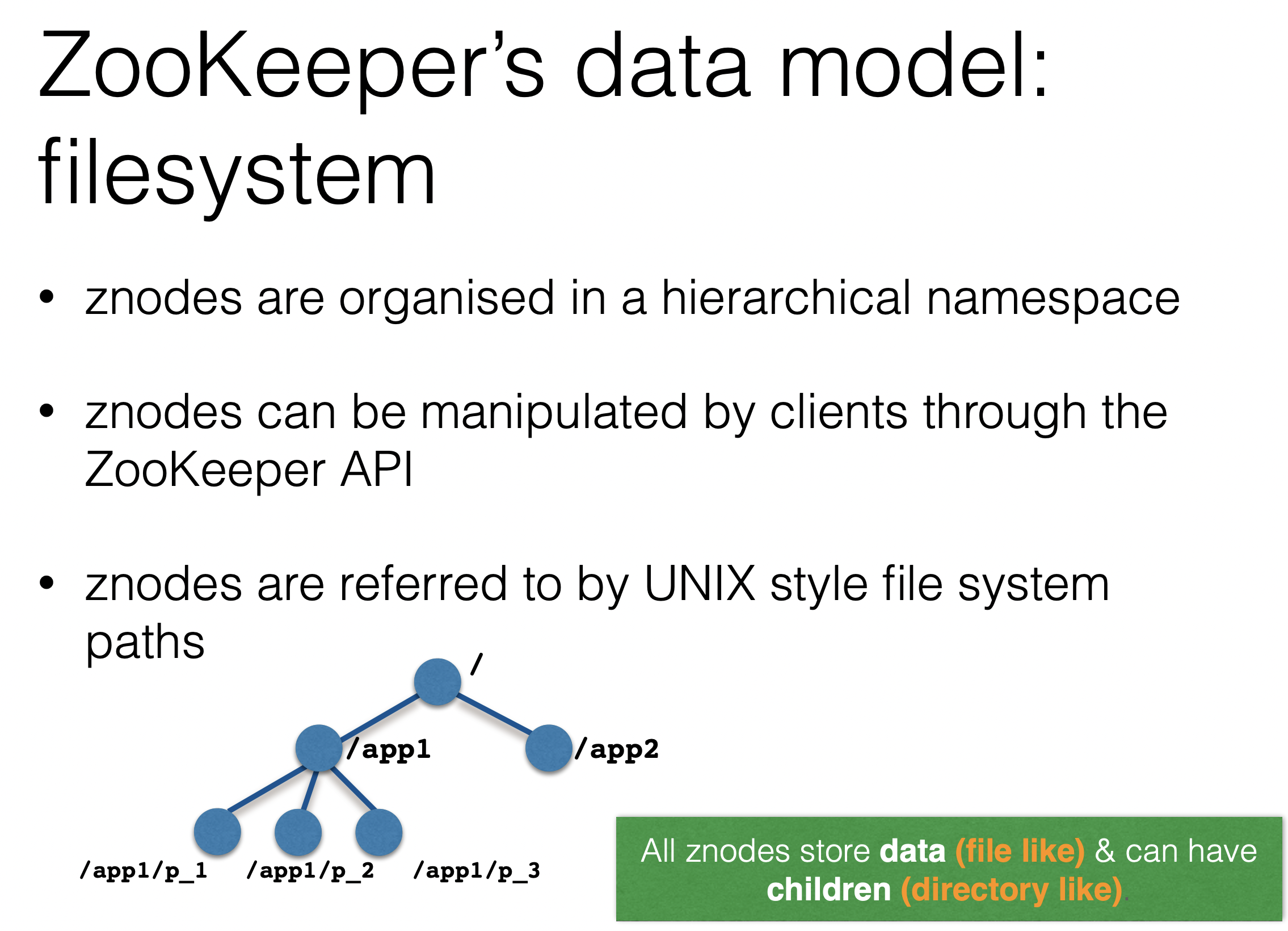
File system analogy
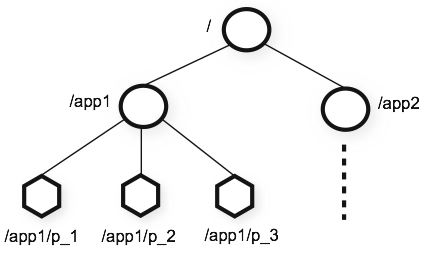
- The name space provided by ZooKeeper is much like that of a standard file system. A name is a sequence of path elements separated by a slash (/). Every node in ZooKeeper’s name space is identified by a path.
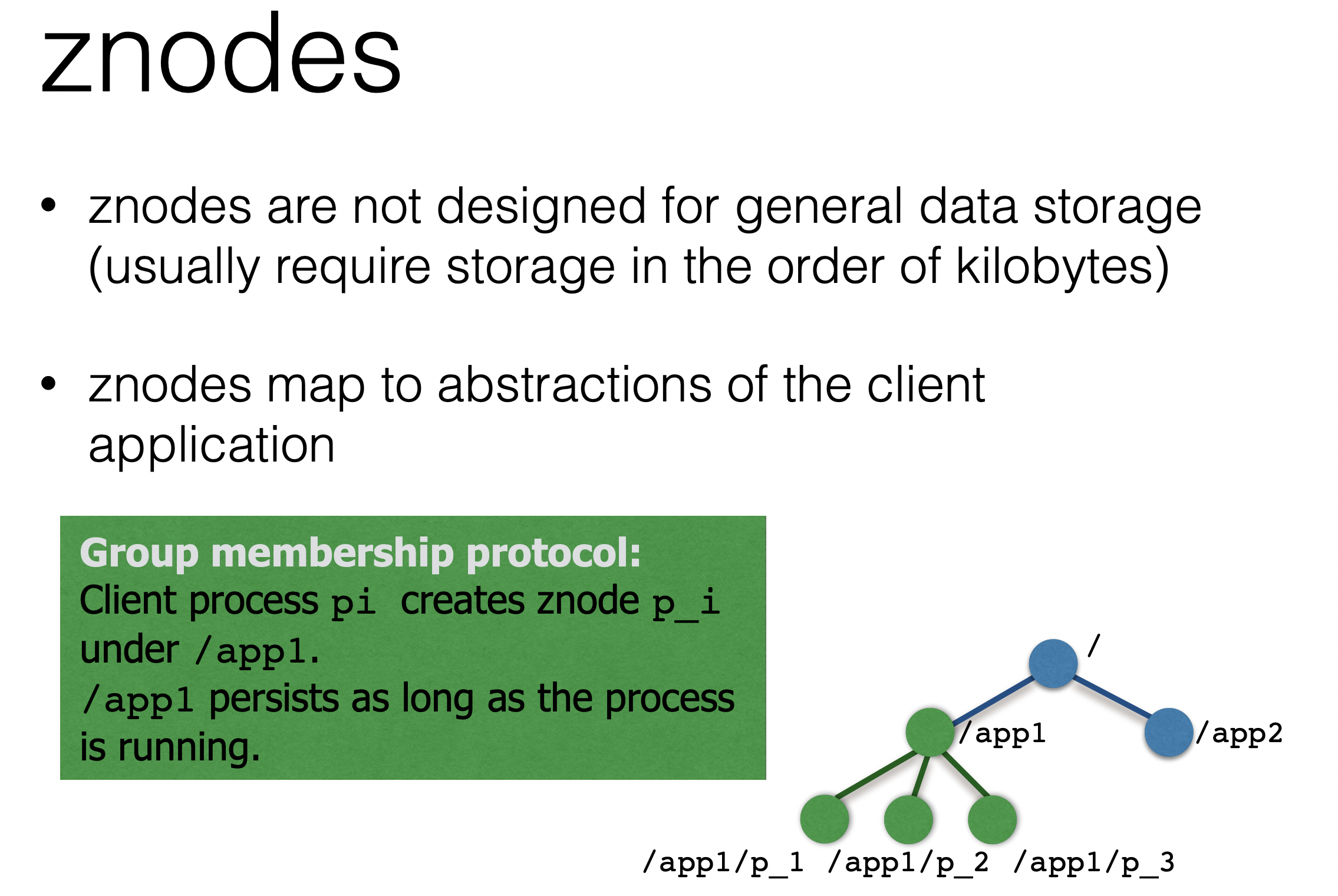
- Unlike standard file systems, each node in a ZooKeeper namespace can have data associated with it as well as children. It is like having a file-system that allows a file to also be a directory. (ZooKeeper was designed to store coordination data: status information, configuration, location information, etc., so the data stored at each node is usually small, in the byte to kilobyte range.)
- Znodes maintain a stat structure that includes version numbers for data changes, ACL changes, and timestamps, to allow cache validations and coordinated updates.
- Each time a znode’s data changes, the version number increases.
- For instance, whenever a client retrieves data it also receives the version of the data.
- The data stored at each znode in a namespace is read and written atomically. Reads get all the data bytes associated with a znode and a write replaces all the data. Each node has an Access Control List (ACL) that restricts who can do what.


Watches
- Watches set against data or path changes
- Ordered with respect to other events, other watches, and asynchronous replies.
- A client will see a watch event for a node it is watching before seeing the new data that corresponds to that node.
- The order of watch events corresponds to the order of the updates as seen by the ZooKeeper service
- One time notifications; must be reset, changes can be missed between notification and reset of the watch
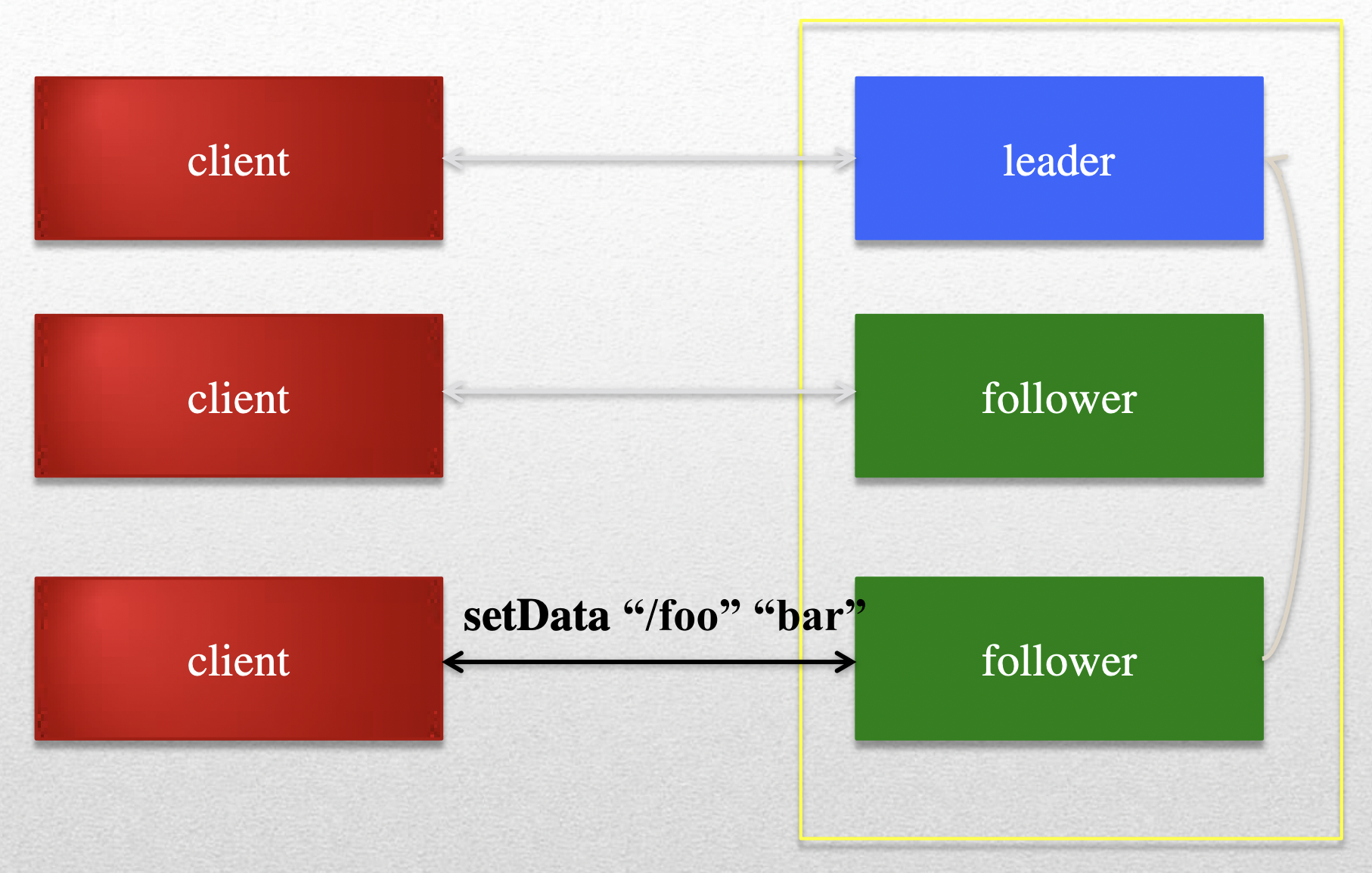
The leader executes all write requests forwarded by followers. The leader then broadcasts the changes.
API
Creation API
- create(path, data, flags)
- flags enables a client to select the type of znode: regular or ephemeral, and set the sequential flag
- delete(path, version)
- Deletes the znode path if that znode is at the expected version
- setData(path, data, version)
- Writes data to znode path if the version number is the current version of the znode
Get/Watch API
- exists(path, watch)
- Returns true if the znode with path name exists,
- getData(path, watch)
- Returns the data and metadata (eg, version information)
- getChildren(path, watch)
- Returns the set of names of the children of a znode
Other API
- sync(path)
- Waits for all updates pending at the start of the operation to propagate to the server that the client is connected to
- multi(ops)
- executes multiple ZooKeeper operations or none of them.
Implementation Details
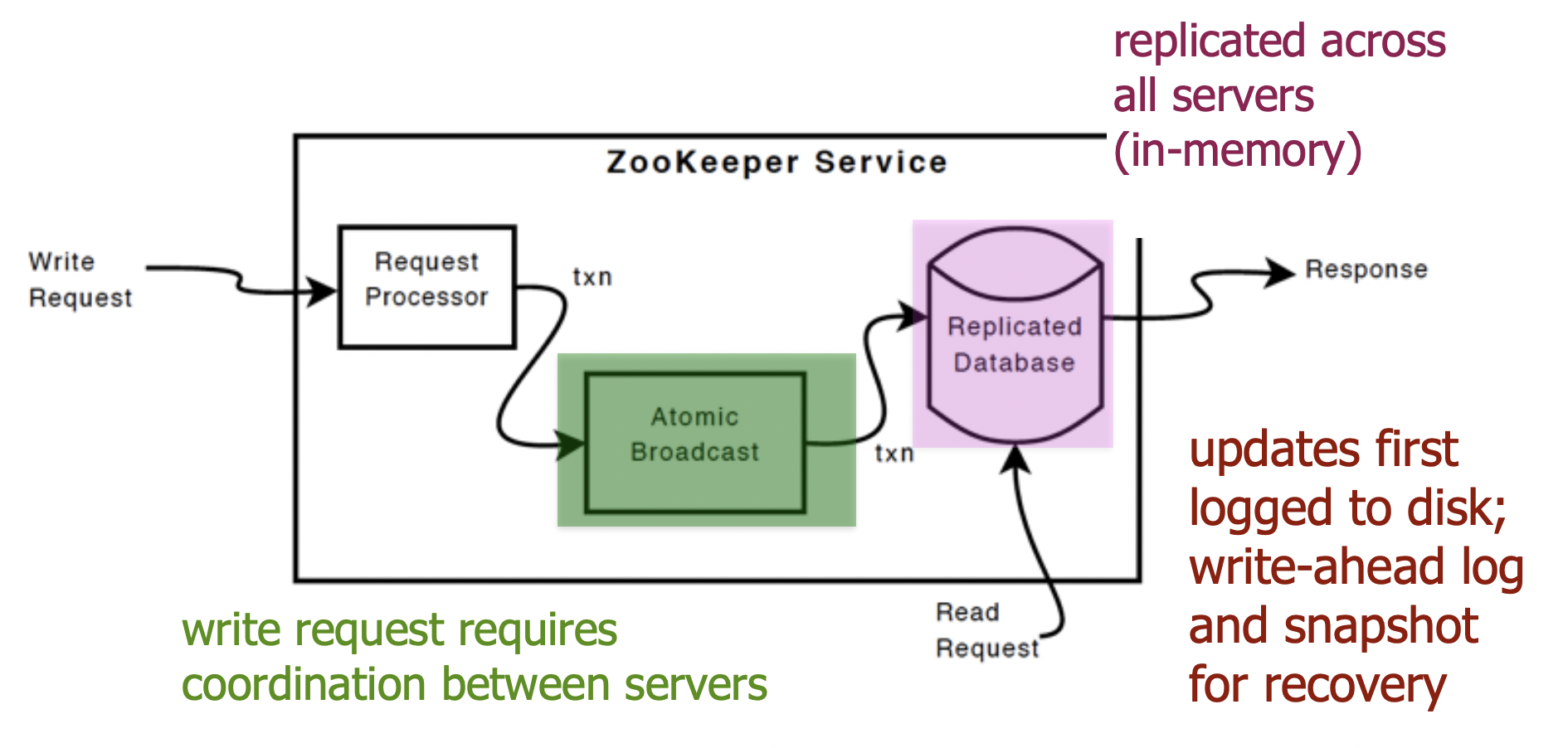
The replicated database is an in-memory database containing the entire data tree. Updates are logged to disk for recoverability, and writes are serialized to disk before they are applied to the in-memory database.
ZooKeeper uses a custom atomic messaging protocol. Since the messaging layer is atomic, ZooKeeper can guarantee that the local replicas never diverge. When the leader receives a write request, it calculates what the state of the system is when the write is to be applied and transforms this into a transaction that captures this new state.
Uses of Zookeeper
- The programming interface to ZooKeeper is deliberately simple. With it, however, you can implement higher order operations, such as synchronizations primitives, group membership, ownership, etc.
- Two main categories
- Service management
- Distributed Locking: Locking and synchronization service
ZooKeeper was not implemented to be a large datastore.
Discovery of hosts
A typical use case for ephemeral nodes is when using ZooKeeper for discovery of hosts in your distributed system. Each server can then publish its IP address in an ephemeral node, and should a server loose connectivity with ZooKeeper and fail to reconnect within the session timeout, then its information is deleted.
- Configuration management: Up-to-date system config info for a joining node
- Cluster management: Joining / leaving of nodes, real-time node status
- Highly reliable data registry
- Naming service
- Identifying nodes in a cluster by name (“DNS” for nodes)
Ephemeral nodes
Leader election
An easy way of doing leader election with ZooKeeper is to let every server publish its information in a zNode that is both sequential and ephemeral.
Then, whichever server has the lowest sequential zNode is the leader. If the leader or any other server for that matter, goes offline, its session dies and its ephemeral node is removed, and all other servers can observe who is the new leader.
If we use write for leader instead of lowest sequential zNode, then Zookeeper will send the notification to all servers and all servers will try to write to the zookeeper to become a new leader at the same time creating a herd effect.
- Electing a node as leader for coordination purposes
Same leader election can also be used for locking a resource
Building blocks
- Persistent Znode: This acts as the parent directory for your lock (e.g., /lock_parent). It’s always present, even if the client that created it disconnects.
- Ephemeral Znode: This is a special znode that exists only as long as the client that created it maintains an active session with ZooKeeper. If the client crashes, the znode is automatically deleted. This is crucial for preventing deadlocks.
- Ephemeral Sequential Znode: This is an ephemeral znode that also has a monotonically increasing sequence number automatically appended to its name by ZooKeeper. This sequence number is used to determine the order of clients waiting for the lock.
Avoiding the “Herd Effect”
If many clients are waiting for a lock, and one client releases it, you don’t want all the waiting clients to wake up at the same time and flood the ZooKeeper server with requests.
Message queue
With the use of watchers one can implement a message queue by letting all clients interested in a certain topic register a watcher on a zNode for that topic, and messages regarding that topic can be broadcast to all the clients by writing to that zNode.
- An important thing to note about watchers though, is that they’re always one shot, so if you want further updates to that zNode you have to re-register them. This implies that you might loose an update in between receiving one and re-registering, but you can detect this by utilizing the version number of the zNode. If, however, every version is important, then sequential zNodes is the way to go.
Other usecases
https://zookeeper.apache.org/doc/r3.6.1/recipes.html
Ref:
- https://zookeeper.apache.org/doc/r3.1.2/zookeeperOver.html
- https://timilearning.com/posts/mit-6.824/lecture-8-zookeeper/#zookeeper-can-scale-linearly